Why brand visibility now spans search and AI
A brand audit used to mean a sweep of Google rankings and a check for off-brand pages on the first SERP. That work still matters, but it no longer describes where buyers actually encounter a brand. ChatGPT reached 900 million weekly active users by February 2026, and Google's AI Overviews now appear in 60.32% of U.S. queries as of November 2025.
Each surface picks sources differently. Perplexity cited sources in 95% of search responses in 2024, compared to ChatGPT's 60%. Gemini, embedded inside Google Search, pulls from a different index than ChatGPT, which runs on OpenAI's partner data. A one-time brand audit can't track movement across all of them. The rest of this article details a repeatable framework built around six measurable signals.
What a modern brand audit covers
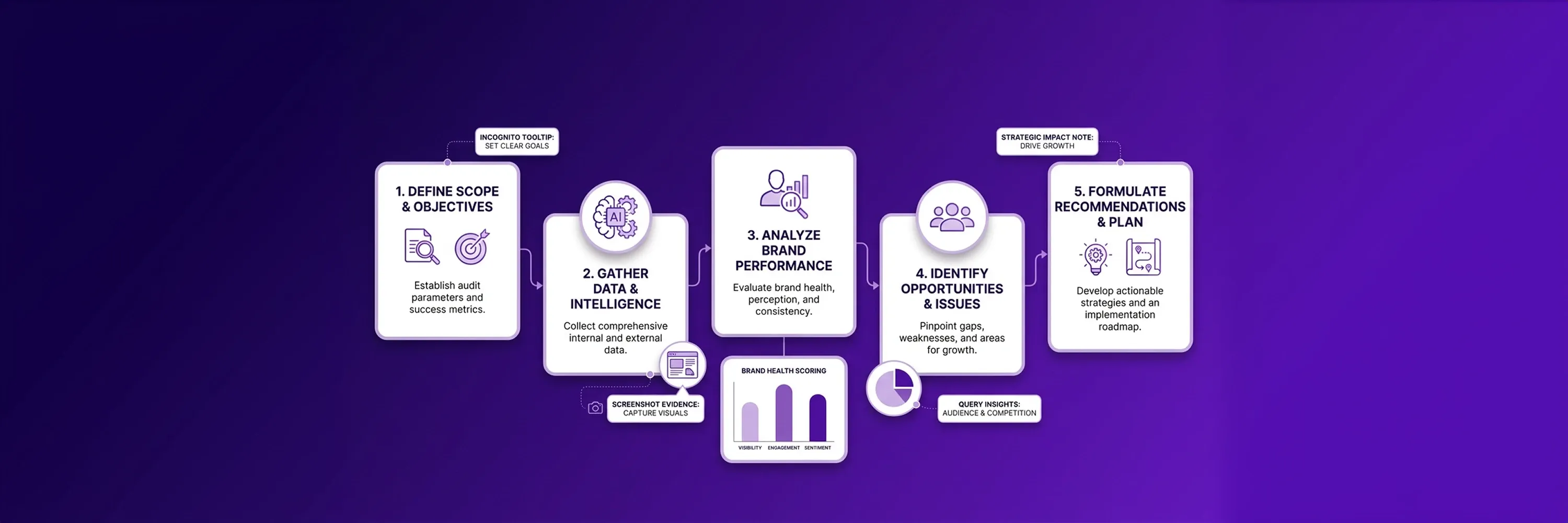
A modern brand audit measures two things at once. The first is how the brand appears in classic search results across owned pages, third-party mentions, reviews, and any negative or off-brand listings. The second is how AI engines represent the brand inside generated answers, which is a separate problem with separate inputs.
This kind of brand analysis differs from a traditional SEO audit because rankings alone don't predict whether ChatGPT will quote a page or whether Perplexity will cite it as a source. The brand audit is also broader than a reputation sweep, because AI engines summarize a brand without surfacing the reviews a reputation tool would flag.
The six signal categories covered below form the diagnostic backbone:
-
Branded SERP control
-
Citation frequency in AI answers
-
Entity consistency across the web
-
Content extractability
-
Third-party authority
-
Sentiment in AI-generated answers
The goal is measurable visibility tied to brand performance.
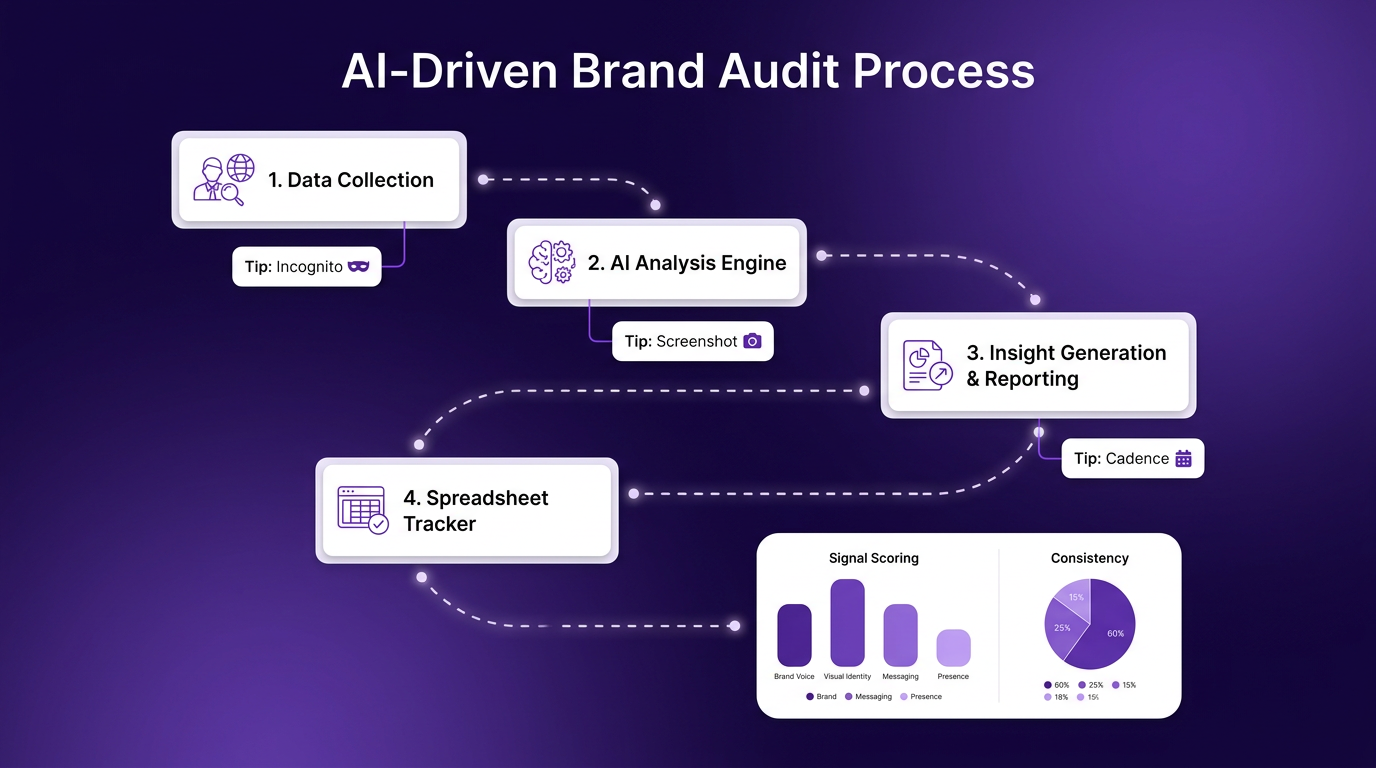
Six signals to measure in a brand audit
Each signal below has its own measurement method and its own thresholds for what a healthy result looks like. Together they feed a single scoring sheet that drives the prioritization step later in the article.
Branded SERP control
Start with a fresh incognito session and run the brand name, then add modifiers: "[brand] reviews," "[brand] pricing," "[brand] alternatives," "[brand] vs [competitor]," and "is [brand] legit." Record the first two pages for each query. Tag every result as owned, partner, neutral third-party, review aggregator, negative, or off-brand.
Score each query from 0 to 10 based on how many of the top 10 results the brand controls directly or through favorable third parties. A red flag is any negative review or competitor comparison ranking in positions 1 through 5 for the bare brand name. Another red flag is a Reddit thread outranking the homepage on a "[brand] reviews" query, because Google AI Overviews pulls heavily from Reddit at 21% of citations, which means a hostile thread shapes both the SERP and the AI summary above it.
Citation frequency in AI answers
Build a query set in three buckets. Use category queries ("best CRM for small B2B teams") and comparison queries ("[brand] vs [competitor]"); include problem-based queries ("how to reduce SaaS churn") as a separate bucket. Run each query in ChatGPT, Perplexity, Gemini, and Google AI Overviews. Log whether the brand was cited, the exact source URL used, the position in the answer, and which competitors appeared more often.
Comparison queries trigger AI Overviews 95.4% of the time, per Seer Interactive's analysis of 49,353 queries, so they deserve heavy weighting in the query set. Look for patterns in which content types get pulled. Perplexity rewards research-heavy posts that themselves cite credible sources, while ChatGPT pulls more from documentation and definitional content. If the brand is invisible across 80% of category queries, citation frequency is the binding constraint on brand performance, and content fixes come before everything else.