Introduction
The digital search landscape is undergoing a shift toward zero-click environments. Tools like ChatGPT and Google’s AI Overviews generate answers directly on the results page. Traditional search engine optimization relied on keyword density and backlink volume to rank web pages. Today, large language models prioritize machine-readable structure, entity signals, and robust data relationships. Consequently, a perfect technical score from a standard web page SEO checker means little if the underlying site architecture lacks the specific signals that generative engines require.
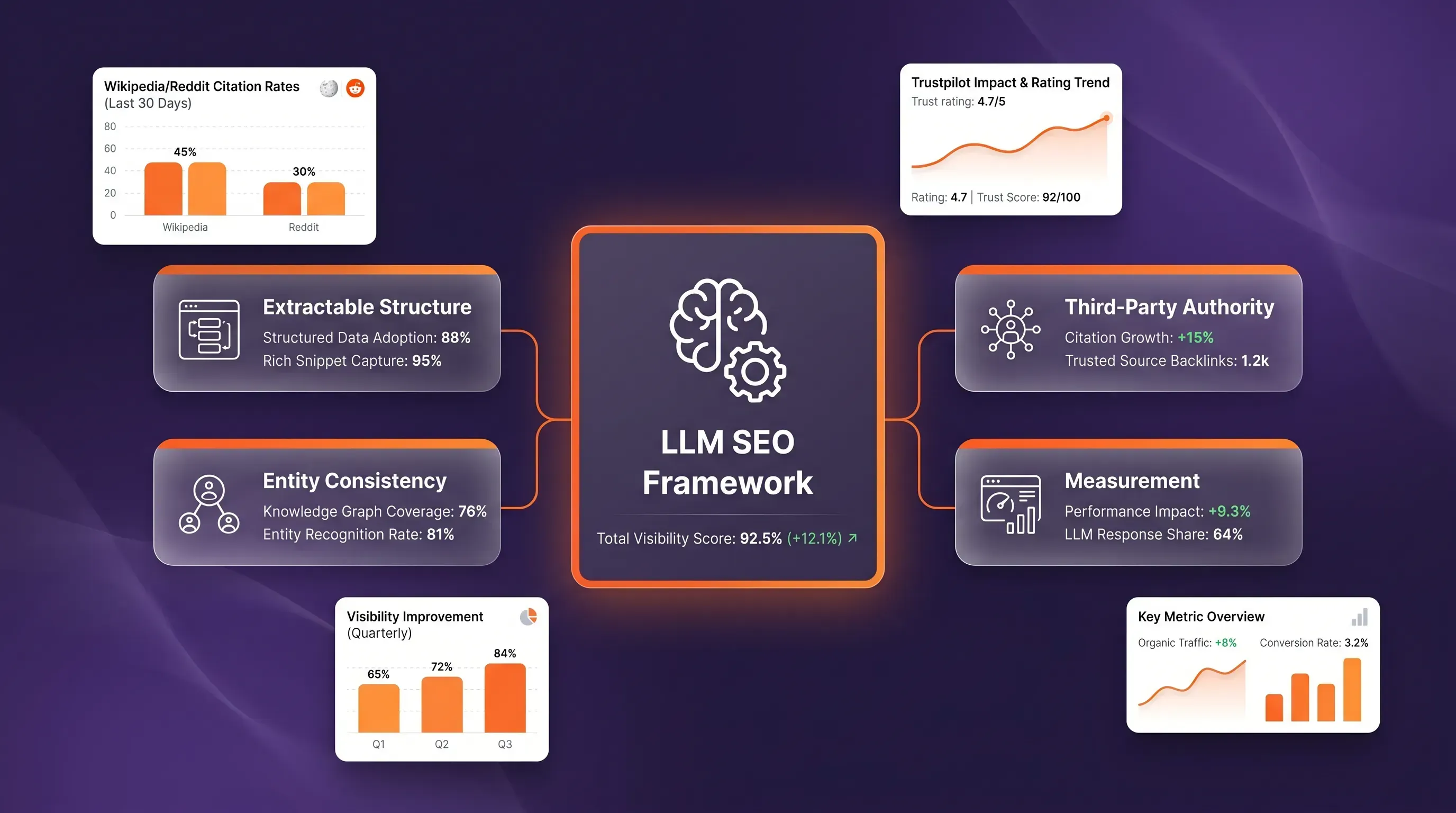
This change makes conventional ranking metrics insufficient for modern visibility. Recent behavioral data indicates that 58.5% of US searches and 59.7% of EU searches end without clicks to websites, keeping users entirely within the AI-generated interface. This new reality requires specialized technical evaluations that look beyond human-readable content. The following sections outline the methodology for evaluating website architecture, configuring crawler accessibility, and adapting traditional audit workflows to meet the demands of Generative Engine Optimization (GEO).
Divergence Between Traditional Scores and AI Citation Readiness
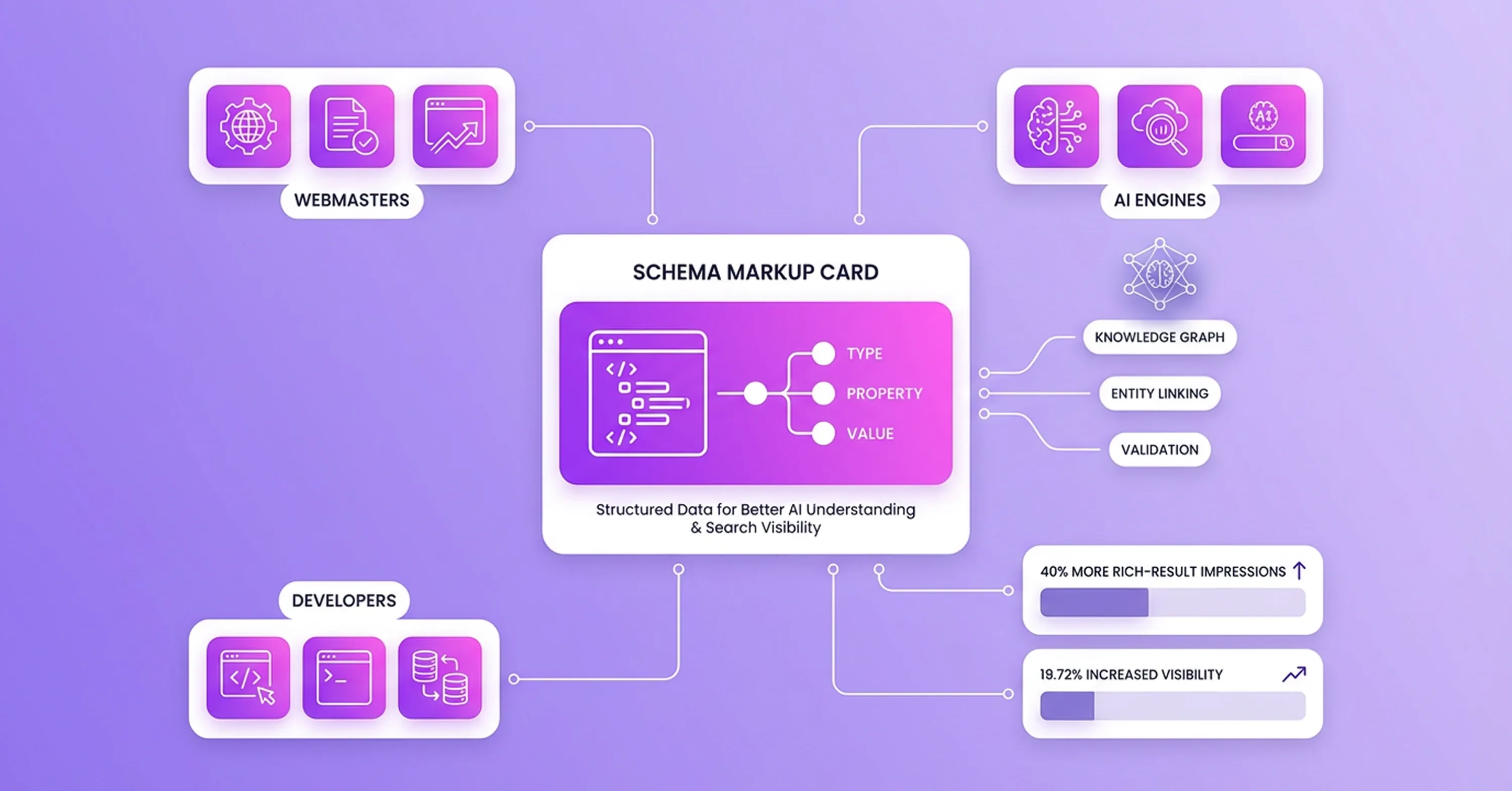
Traditional audit workflows rely on SEO tools that measure keyword density, backlink profiles, and page load speed to calculate a technical score. However, even a 100/100 score on these platforms does not guarantee visibility in modern artificial intelligence (AI) engines. AI systems do not evaluate pages the way legacy search algorithms do. Generative models extract entities, relationships, and facts to synthesize answers rather than simply matching keywords to user queries.
Because of this shift, Tech SEO Connect 2025 found that traditional SEO metrics predict only 4–7% of AI citations. This gap highlights why legacy auditing methods lack the precision required in the current search landscape. Large language models (LLMs) struggle to understand the context of web content without structured data and explicit entity connections. Consequently, a recent GEOReport audit analysis shows that more than 80% of indexed pages fail to appear in generative reasoning processes.
Website publishers can no longer rely on keyword matching alone. Earning AI citations requires building content architecture around fact density rather than search volume. When audits focus on machine-readable structures, brands gain the ability to compete in zero-click environments. Engineers are rebuilding their evaluation criteria to prioritize fact extraction over simple term frequency.
Technical Auditing Guidelines for AI Bots
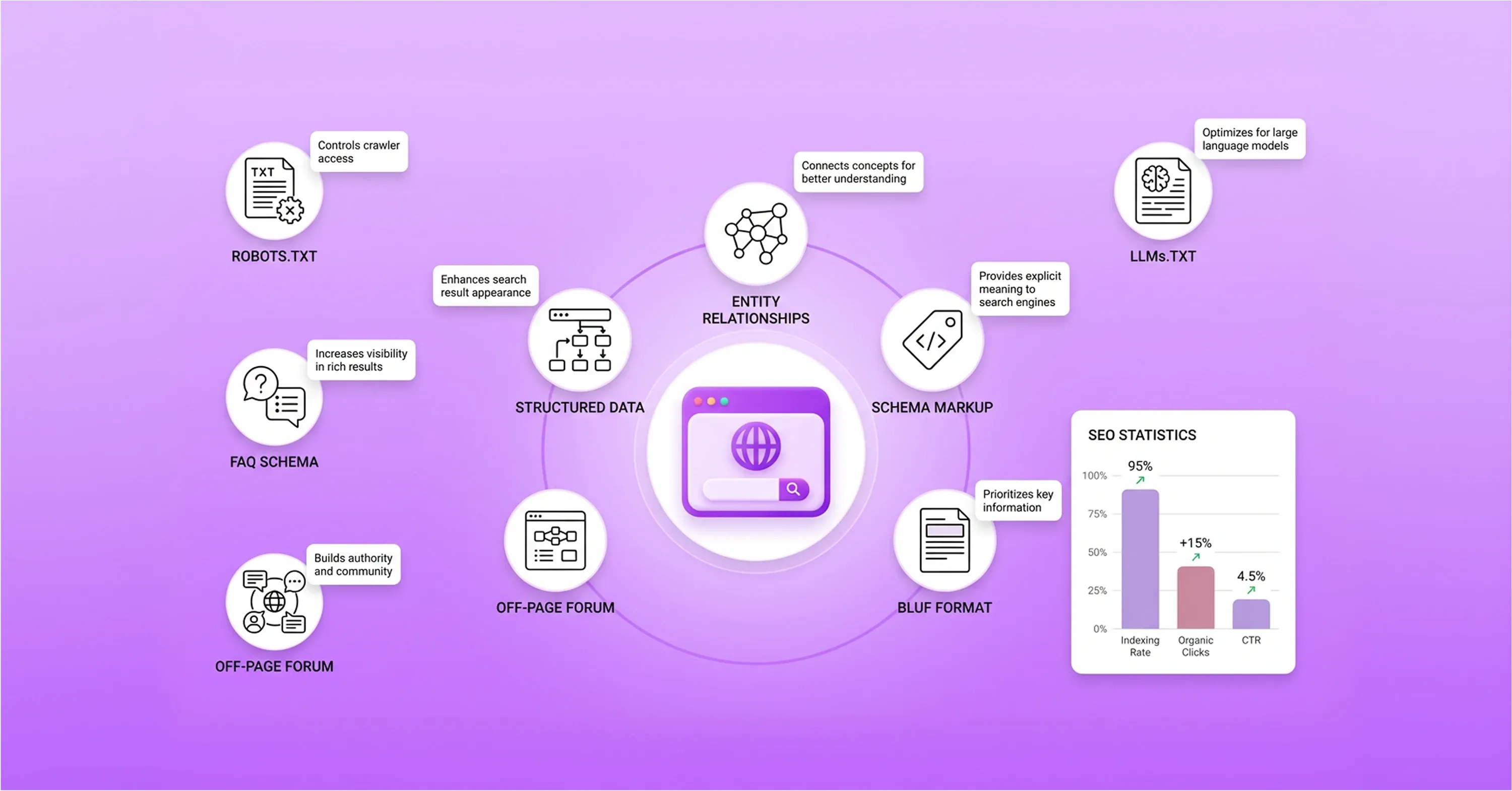
After engineers rebuild these evaluation criteria, system administrators establish the foundation for technical readiness by configuring site accessibility for AI crawlers. Search platforms deploy specialized bots to scrape content for training and real-time retrieval. If these bots cannot access the website architecture, even the best entity relationships remain invisible to generative engines.
A modern technical SEO audit prioritizes crawler configurations that grant explicit permission to these new user agents. Engineers evaluate server logs precisely because a single misconfigured directive can block major AI platforms from reading the site. Webmasters verify that the website infrastructure supports the distinct fetching patterns of machine-learning models.
Traditional crawlers prioritize human-readable Hypertext Markup Language (HTML), but AI bots look for machine-readable text formats and structured data payloads. Website administrators who integrate these accessibility checks into routine website evaluations strengthen their overall optimization strategy. They also prevent unexpected drops in organic visibility by identifying and resolving blockages early.